Review ItemSAGE Paper
| Paper Title | ItemSage: Learning Product Embeddings for Shopping Recommendations at Pinterest |
| Informal name | ItemSAGE paper |
| Date | 2022-05 |
| Link | https://arxiv.org/abs/2205.11728 |
| Code | Example of PinSAGE on MovieLens |
Quick notes:
- What’s the role of the CLS token in this case? (global???)
- If applied to Zillow, the multi-task learning can integrate user’s preference for property types as a supervision task.
Details of ItemSAGE implementation
- They already have the following existing models:
- PinSAGE: A scalable implementation of GraphSage that aggregates visual information along with graph information to produce image embeddings (each image is a “pin”)
- SearchSAGE: Search query embedding model trained by fine-tuning DistilBERT. It’s trained on (search query, engaged pin) pairs from search logs => Optimize cosine similarity
- Problem framing for the ItemSAGE model:
- Each item are represented by a sequence of image and text features.
- These features –input–> ItemSAGE model –output–> Item embeddings
- These item embeddings are trained on (query, engaged item) pairs. Objective: minimize cosine similarity between Item embeddings and query embeddings (which was fixed and created by PinSAGE and SearchSAGE model above)
- Note that “query” is defined as both text search query and image query in the “similar product” module.
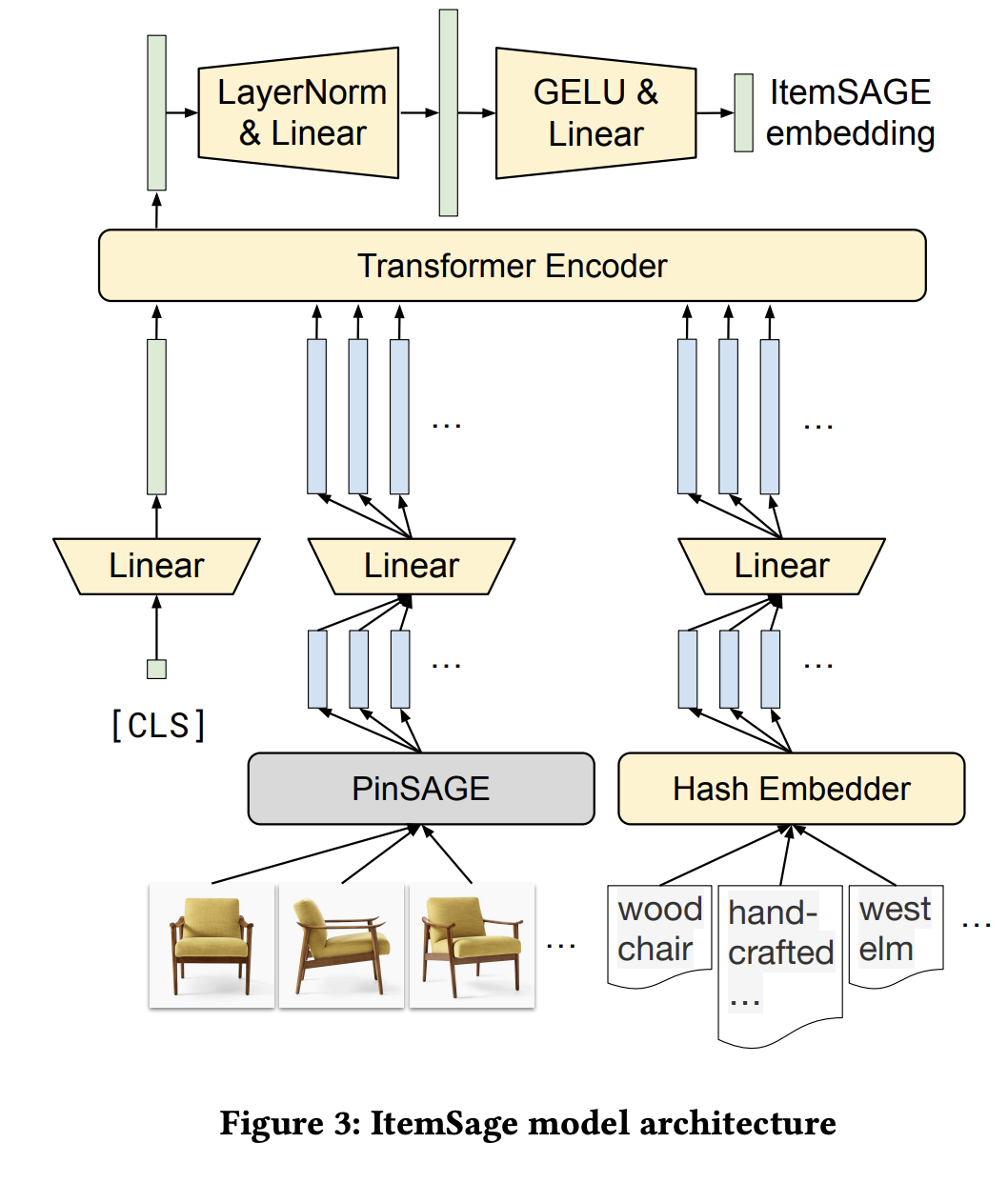
- Model architecture:
- PinSAGE is leveraged - and freeze to handle image features while text feature weights are learnable.
- The context-aware embedding of global [CLS] token is the futher process as embeddings
- Only use 1-layer transformer block (8-heads self-attention + feed forward), they experimented with deeper transformer encoder but yield no improvment in offline metrics.
- Hash Embedder was used to embed text feature -> reduce the vocabulary size to 100K. (tbh I don’t fully understand the implementation of hash embedder - future reading required).
- Dimensions:
- Various embedding output: 256 for hash embedder, 256 for PinSAGE, [CLS] not mentioned
- Embedding output –projection–> 512 –Transformer–> 512 –MLP2Layer–> 256
- Color code below: Yellow: Learnable weights, Blue: Features, Green: Item embedding
- Loss:
- Using softmax-like loss, not softmax exactly due to high computational cost
- Estimate softmax using 2 types of negative sample:
- In-batch negatives: Other items in the same batch (different they are positive to other query) - If only use this, popular items will be negatively biased, thus also use
- Random negatives: Same size as batch size
- Multi-task learning: Mixing (query, engaged items) of different types in the same batch
- Query types: Close up (image), Search (text)
- Engagement types: Clicks, Save, Checkouts, Add-to-cart
- Control sampling proportion to control the weights of different tasks (experimentally equal number of sample each batch (B/K) for each task yield the best result)
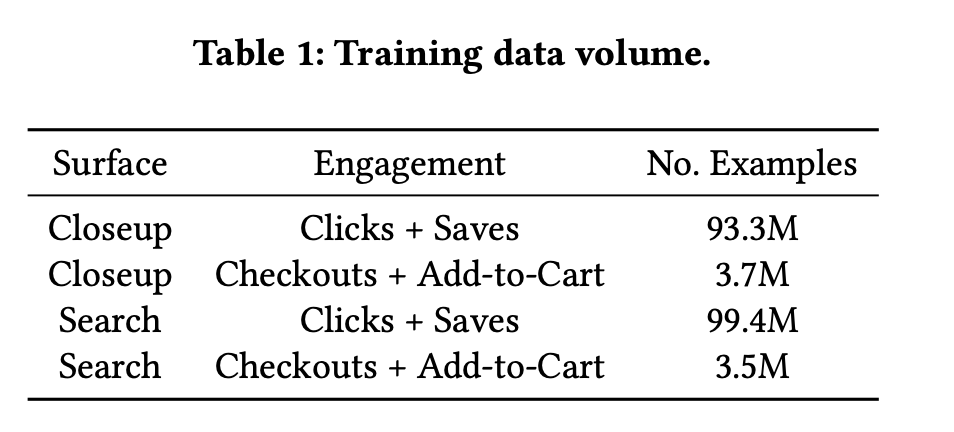
- Data volume
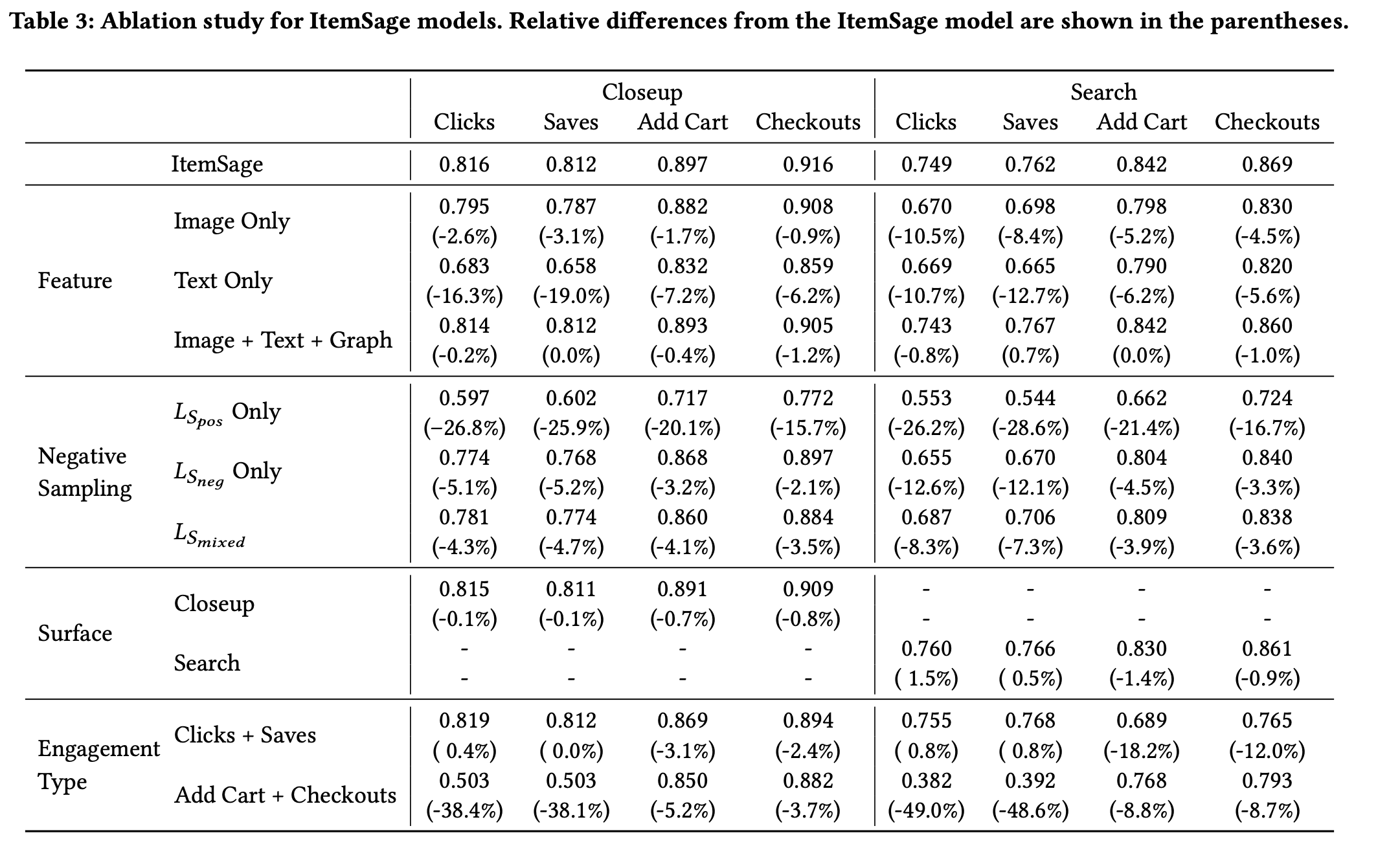
- Ablation study: Multi-modality significantly improve model performance, so does multi-task.
- Feature ablation: The text-only and Image Only has less information than ItemSage while the Image+Text+Graph model has more information (graph). The result shows that while the single-modal models outperform the baselines, Image+Text multi-modal does improve the performance significantly. Mean while the additional graph information doesn’t provide performance gain.
- Loss ablation: Multiple source of negative example prevent the model to converge into a degenerate state.
- Task ablation: Multi-task learning improve performance for data-sparse tasks like add-to-cart and checkout, while not losing performance significantly on other tasks.
- Online Experiment: Significant improve in Click, Purchases, and GMV across different surfaces.
Final thoughts and personal takeaways
- Training embeddings that are suitable with cosin similarity (cross-product) is a great way to use deep-learning technique for production-ready recommendation system: High training time and cost but O(1) inference time.
- Ablation study show that the combination of Multi-modality + Multi-task + Multi-negative sampling greatly improve the model’s generalization and performance.
- Multi-task helps solving label sparsity problem.
- Transformer encoder does not need to be complex or deep to do the job.
