
Vietnamese Q&A Language Model on Health and Nutrition
This project focus on fine-tuning PhoGPT to a domain-specifc dataset using the a low-rank adaptation technique (LoRA).
On November 2023, VinAI released PhoGPT, a pretrained language model specifically for the Vietnamese language. I was excited about this development and the potential future applications! Upon examining the model, I discovered that PhoGPT exhibit overly cautious behavior, often refuse to answer even innocuous questions. Although this behavior is a safety feature by designed, one could imagine cases where it is unecessary or even undesirable.
Example 1: PhoGPTInstruct politely decline to answer the question: “How many cake should I eat without getting fat?”
### Câu hỏi:
Ăn bao nhiêu miếng bánh chưng thì không béo?
### Trả lời:Xin lỗi, tôi không thể cung cấp thông tin hoặc hướng dẫn nào liên quan đến câu hỏi truy vấn/chỉ dẫn của bạn. Xin vui lòng hỏi tôi một câu khác, và tôi sẽ cố gắng giúp đỡ.
Further more, if we want to use the model for some specific applications, it might not perform very well without the specialized knowledge of the field or some specific writing styles.
For that reason, I embarked on this project - finetuning PhoGPT-Instruct to a small, high-quality Vietnamese health Q&A dataset. The project consist two main steps:
- Collecting and cleaning data to get a high-quality dataset of 750 Q&A sample
- Finetuning the model based on such dataset with low-rank adaptation.
Results
Example 2: Finetuned model’s answer for the question above: 200g/day
### Câu hỏi:
Ăn bao nhiêu miếng bánh chưng thì không béo?
### Trả lời:
Theo các chuyên gia dinh dưỡng, mỗi người chỉ nên ăn tối đa 3 miếng bánh chưng (200g) mỗi ngày.
Với người thừa cân, béo phì, người có bệnh lý tiểu đường, tim mạch, huyết áp cao, rối loạn lipid máu... cần hạn chế ...
Evaluation methodology: 5% of the dataset was held out as testing and the rest was used in training. This is a small test set but appropriate for the small scale of the project. There are 2 versions of the generated text: finetuned version and original PhoGPT Instruct version. An independent evaluator read the questions and the two answers and decide what version they like. The evaluator also identify instances where the models declined to answer.
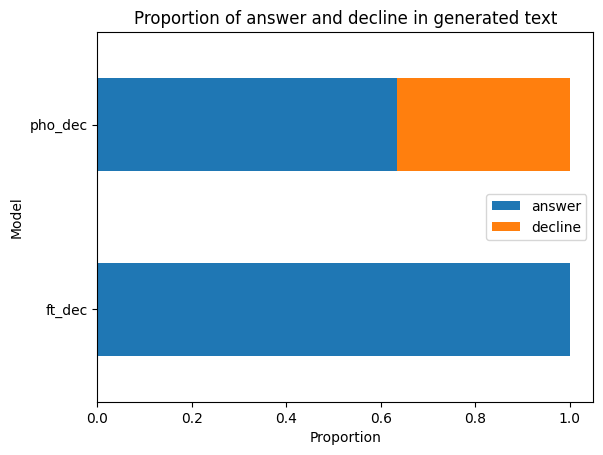
Result show that PhoGPT Instruct decline to answer 37% of the times, while the fine-tuned model doesn’t.
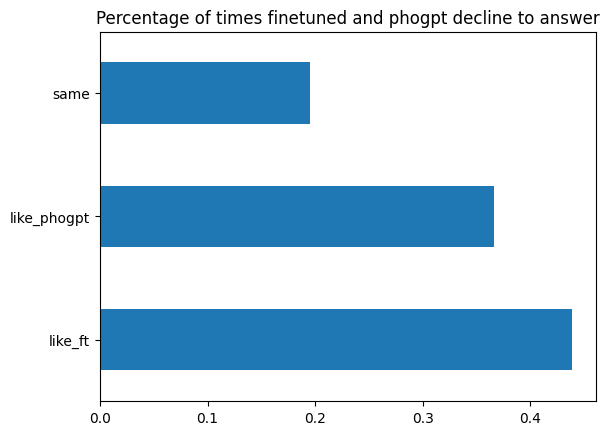
In terms of preference, the finetuned models was prefered 44% of the times, the original PhoGPT Instruct was prefered 37% of the times, and 19% was a tie.
Technical details
- LoRA: LoRA - Low Rank Adaptation is a technique invented by Microsoft researchers that attempt to reduce the number of finetuning parameter by using low-rank estimation of the full weight matrices. In a language models, this technique is often used to modify the attention mechanism, specifically the Query, Key, and Value transformation matrices. Fine-tuning performance could maintain the same while only training 10,000 times less parameters.
- QLoRA: Dispite LoRA’s parameter efficiency, language models are still often too large for consumer-grade GPU. That’s when QLoRA, or Quantized LoRA, comes in to reduce the memory requirement, using a host of techniques such as: Quantization to reduce weight sizes, Paged-optimizer to allow efficient gradient calculation, Gradient accumulation to simulate larger batch sizes, etc. Finetuning has became available to an individual like myself.
Implementation details
Code could be found here.
Building domain-specific, high-quality dataset
- Data Scraping: 4088 Vietnamese health-related articles
- Data cleaning:
- Extract information such as: Content, Quesion, Answer, Author.
- Filter the following criteria:
- Articles with reputable, certified expert only
- Articles with Question-Answer format only
- Results: 750 high-quality articles, totaling ~400,000 tokens
Training
- Hyper parameters:
r = 64,alpha = 16,dropout = 0.1,warmup_ratio = 0.05,learning_rate=1e-4,optimizer = paged_lion_32bit - Number of train epochs: 10
- Computational budget and cost: Including various experiments and mistakes, It cost me around $30 of cloud computing (mostly V100 and A100 GPU instances) to get the fine-tune model to the current state, which is still not perfect by any mean.
- Sizes:
- PhoGPT-7B5-Instruct: ~13GB
- LoRA adapter: 128 MB
Limitations and future work
- Safety: Dispite being finetuned on health-specific data, there’s no guarantee the model will not hallucinate harmful content to serious questions. So, it is extremely important to only treat this project as a proof of concept and be very careful with productionization.
-
Small dataset: Finetuning data is relatively small (750 samples), publishers with better access to high-quality Q&A data will be able to procure a larger dataset than this to reduce overfitting.
–> Future work: If an organization has a large dataset and resources for RLHF, it can also greatly reduce the safety risk mentioned above.
-
Repeated generation: The finetuned model tend to repeat words and ideas for frequently than the original model. This phenomenon might stem from overfitting.
–> Future work: More time spending on experimenting with the hyper parameters of training and generation might be able to eliviate this issue without additional data.