Automated essay scoring
Automated essay scoring (AES) is a task in which machine learning models are used to evaluate the quality of written essays. It is a useful application of machine learning as it can save time and effort required to manually grade essays. Our team conducted a machine learning project on AES as a group project for the Machine Learning class (CS 7641). In this project, we aimed to predict six analytic measures for each essay, including cohesion, syntax, vocabulary, phraseology, grammar, and conventions.
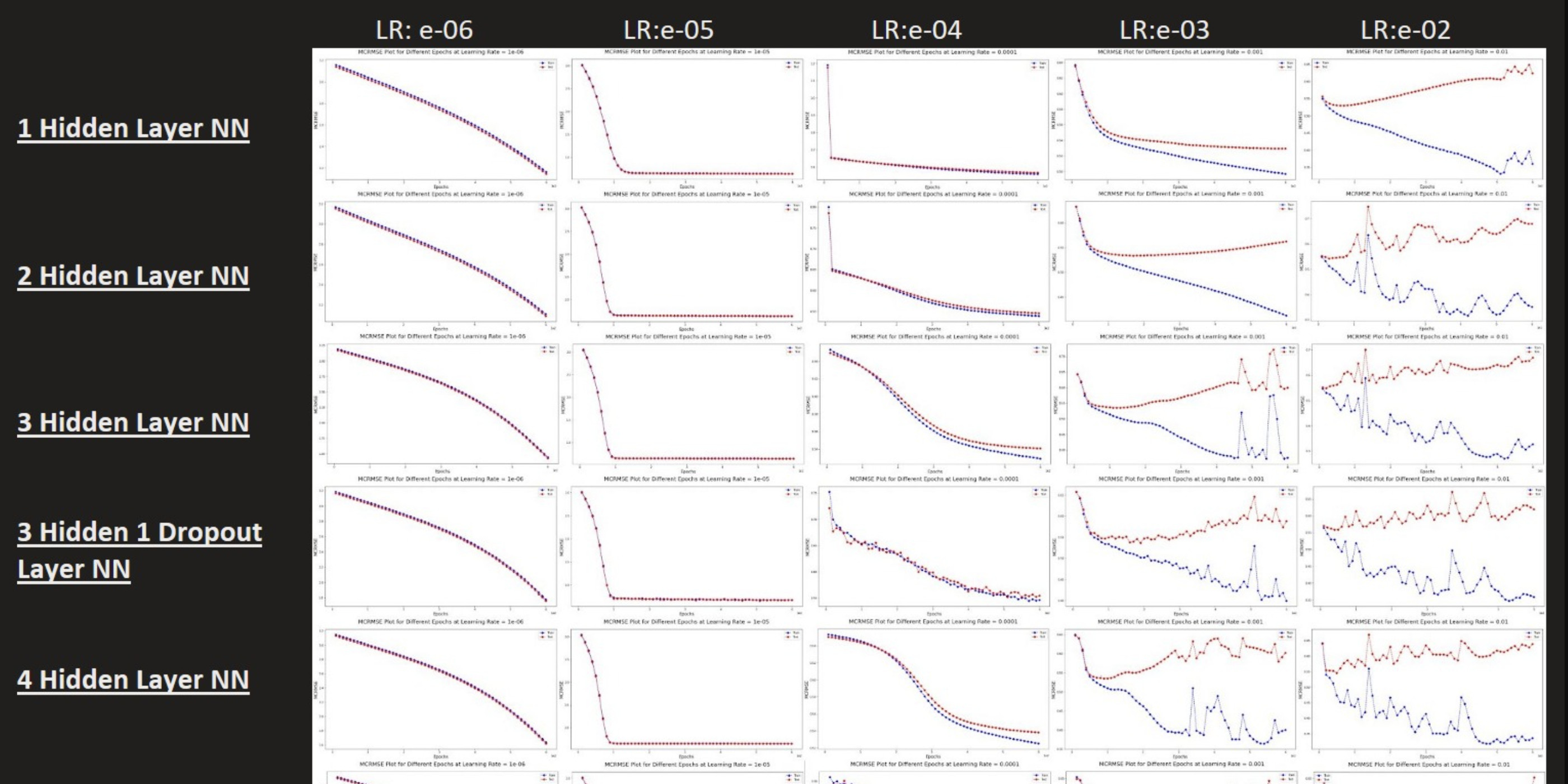
In the field of natural language processing (NLP), there are three common approaches to building machine learning models that work with text data: manually designed features, recurrent neural networks (RNNs), and transformers. Among transformers, the BERT (Bidirectional Encoder Representations from Transformers) architecture has been the state-of-the-art method for NLP tasks in recent years. However, BERT and other pre-trained models have been historically underused for AES.
Our team applied BERT using transfer learning to construct a multi-dimensional AES model, a novel application that leverages BERT’s ability to contextualize sentences and compensates for its weaknesses. We also built models using manually designed features and RNNs for comparison. Additionally, we used unsupervised learning clustering algorithms to create meaningful groupings of students and their essays, providing valuable insights for educators. Overall, we took a methodical approach to this project, using state-of-the-art techniques and considering various approaches to improve the performance of our model.
In conclusion, the BERT-based model performed better than the baseline model, but the RNN model did not outperform the baseline model. This may be due to the well-designed features in the traditional ML baseline or the small dataset available for training. We also found that grammatical errors and typos were the main features separating high and low performers. In the future, we plan to improve the performance of our models by extracting more features from the data, reducing the complexity of the RNN encoder, and experimenting with more sophisticated decoder architectures for the BERT-based model. Overall, our learnings and models from this project offer an interesting new approach to drive value in the classroom.
For more details, please see the full version of the final report HERE.