Generative inpainting
In my Spring 2023 semester at Georgia Tech, I took the CS 7643 Deep Learning class. For the final project, I worked with a team of 3 other students to survey, implement, and evaluate 3 different generative inpainting methods, namely DCGAN, Contextual Attention, and Stable Diffusion.
Image inpainting is one of the image restoration techniques that involves filling in missing or damaged pixels in an image. It has several applications such as object removal, image restoration, etc. Generative inpainting is a class of techniques that use generative models to fill in the missing parts. It is superior to classical approaches due to the ability to ”hallucinate” content from the learned distribution and to do it in a way that is consistent with the context surrounding the missing patch. Recent years have seen significant advancements in the field, especially the shift from GAN-based models to Diffusion-based models with tools like DALLE-2 and Stable diffusion. For this reason, we are motivated to conduct an academic survey study of the generative inpainting techniques. This paper aims to understand the basic principles, differences, strengths, and weaknesses of different inpainting techniques, especially DCGAN, Inpainting with contextual attention, and diffusion-based models.
We have implemented and evaluated these approaches on the Places205 dataset. We found that the diffusion-based model with pre-trained weights performs the best, while DCGAN and Contextual Attention achieve similar level of results. We also found that training these models was highly time-consuming and computationally costly and that using pre-trained weights is the best option.
Table 1 below shows the quantitative evaluation of a DCGAN model, a Contextual Attention model, and a pre-trained diffusion model on the inpainting task. It is clear that the Stable Diffusion model vastly outperformed the other two models on FID, highlighting the effectiveness of the diffusion method. Regarding MSE and MAE, however, the 3 models have quite comparable results.
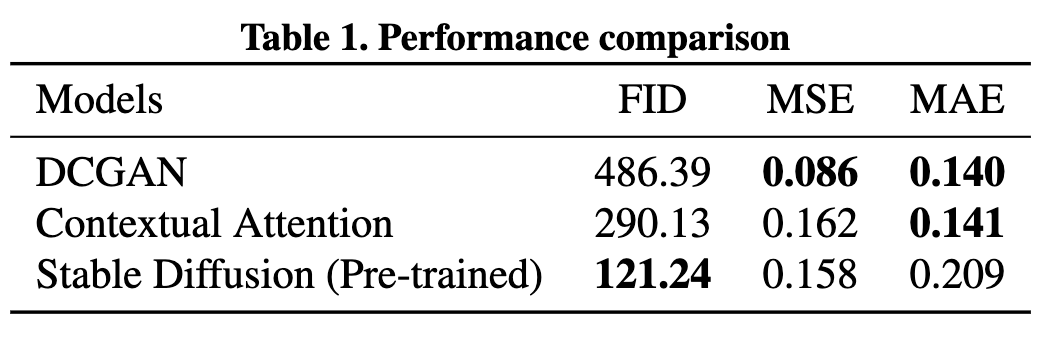
Visually speaking, the output from the Stable Diffusion model is quite natural, only show weakness when zooming into the details. The Stable Diffusion model can also “hallucinate” objects that were not there to fill in the blank. However, this dataset consists mostly of places without many people or other objects, which means hallucinations can be a weakness if comparing the ground truth and the generated image directly using MSE or MAE. The Contextual Attention model demonstrates a good understanding of the macrostructure of the image but its patches are pixelated in nature and lack details, which can be an easy red flag to the human eye. The DCGAN model achieves the best MSE and MAE, but has the worst FID. The low FID performance shows clearly in Figure below, where its patches are foggy and too smooth.

Comparing the quantitative and the qualitative evaluation, FID seems to align better with human perception when it comes to evaluating the in-painting task. According to this metric, stable diffusion is the best model overall.
Github: github.com/trantrikien239/generative-inpainting-survey
Project report
